Building Windsurf's Web Search Feature: Technical Deep Dive & Best Practices
By Kevin Hou
7 minute read
Windsurf is the world's first AI agent-powered code editor. We launched Web Tools today (web search and URL reading) to the general public and we've been seeing some very interesting use cases already! Because it's a bit of a different architecture than normal, I wanted to give a deep dive into how it works and how you can unlock its full potential.
If you prefer the video version of this blog post with a live demo, feel free to watch the video I've recorded below:
Getting Started
The fastest way to get started is to activate web search in your Windsurf Settings in the bottom right corner of the editor. You can activate it a couple of different ways:
- Ask a question that probably needs the Internet (ie. "What's new in the latest version of NextJS?").
- Use
@webto force a docs search (ie. "@webreact breaking changes"). - Use
@docsto query over a list of docs that we are confident we can read with high quality. (ie. "@docs:anthropic-api-docshow do I stream Haiku in Go?"). - Paste a URL into your message (ie. "https://github.com/vercel/next.js/blob/canary/packages/next/README.md who invented this library?").
Technology
The Cascade agent is already one of the most popular and top performing agents on the market. It's used by hundreds of thousands of developers around the world to build new projects, refactor existing codebases, write unit tests, and so much more. It's incredibly versatile and that's largely due to its ability to know when and how to use its tools.
Cascade has a number of tools available at its disposal, including but not limited to:
- Searching through your local codebases
- Viewing & navigating files
- Writing & editing documents on your machine
- Executing terminal commands on your behalf
- New: Retrieving content from the web
We designed and built Cascade to operate very much as a human would. This is the reason why it's flexible, capable, and performant. Regardless of the size or complexity of the codebase, Cascade will be able to grok through it and provide you with file changes, explanations, and more.
I believe that the future of AI is agents and that agents should mimic the behavior of humans when solving problems. Think about how a human would go about researching a question. For the sake of argument, let's say you want to learn how to create a dynamically generated open-graph image (ie. preview thumbnail image) for a page on your NextJS website.
Architecture
Cascade is the AI agent that powers Windsurf. Web search is a mechanism for external content retrieval and therefore can be considered a "tool" in the agentic execution system. It's structured into three different tools:
- Web Search: Find a list of relevant articles online that pertain to your query or intent. It does not read the contents of the page.
- URL Read: Get the contents of the page and if necessary, create multiple "chunks".
- View a Chunk: If the page gets chunked, read the relevant sections of the page.
Here is an example of an end-to-end NextJS change that required looking up the most recent documentation and reading a specific section of the page in order to generate the correct code:
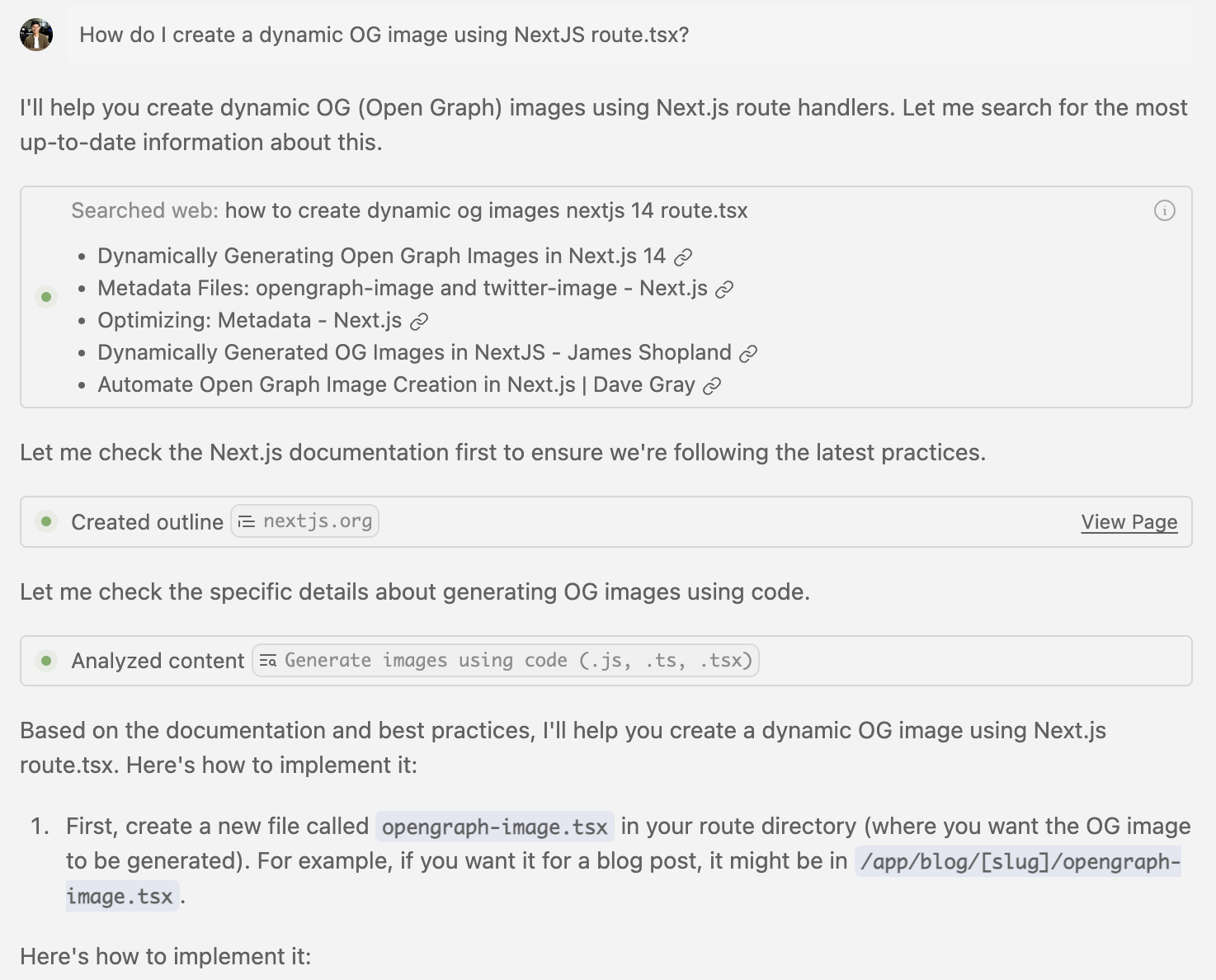
Web Search
Web search is fairly straight forward. We use an LLM to synthesize our conversation and intent into a query and use that query to pull a list of articles that could be helpful. This can include anything from StackOverflow links and GitHub issues to documentation sites and blog posts. This is very similar to a human searching on Google, no need to overthink it!
URL Reading
This step's logic depends a bit on the page in question. It performs a web scrape locally (ie. within your network and on your machine) and gets as much text that it can. This includes headers, body text, links, and more. Notably, if a site has a heavy amount of content rendered client-side, it could get missed. Thankfully, the trend of SSR (Server Side Rendering) is helping on this front.
Short Site: If a site is short, we can ingest its content immediately and use it as context for future steps. The output will simply be text.
Long Site: If a site is long, we don't want to waste time or tokens reading the entire site so we end up creating "chunks". A "chunk" is defined as a section of the page. We have a heuristic to best chunk a page and this is often at the start of a new header. After chunking, we'll construct an outline with a summary of all the chunks on the page (ie. a table of contents). The output of this step will then be an outline. Sometimes this is enough to help with your query, but often the planner will decide it needs to know more and will reach for our third tool: "View Chunk".
Here is an example of the NextJS page broken up into its "chunks":
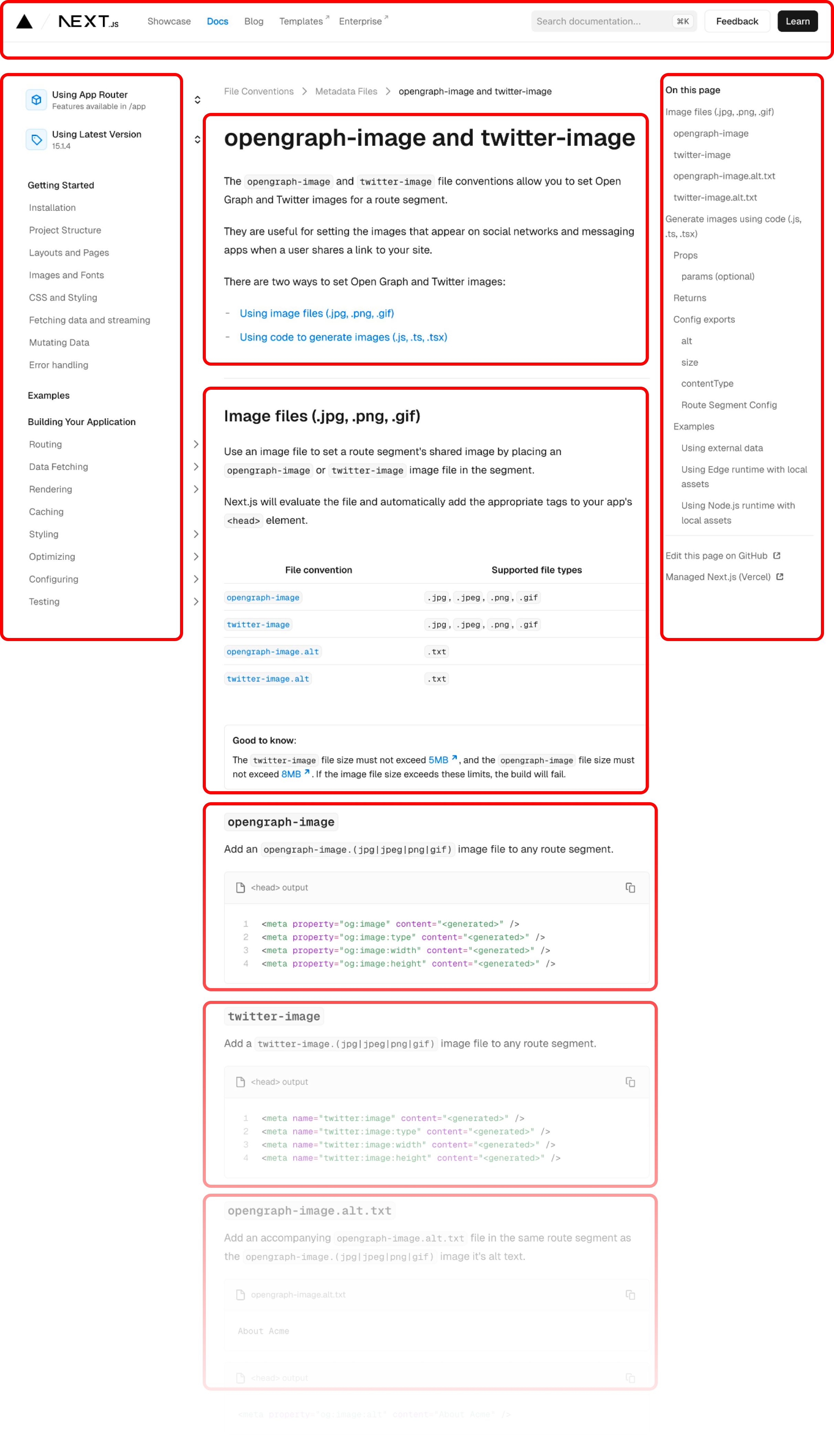
The outline for this page would look something like this:
1Title: Metadata Files: opengraph-image and twitter-image | Next.js 2 3Contents: 4 5- opengraph-image and twitter-image 6- Image files (.jpg, .png, .gif) 7- Generate images using code (.js, .ts, .tsx) 8- Examples 9- ... 10
We don't include every header in the outline because a lot of headers are too small or non-descriptive to be useful.
View Chunk
This tool is only applicable if the page has been chunked. Cascade will decide which parts of the page are relevant to your query and read them.
We perform a few optimizations behind the scenes to make reading the page faster, more targeted, and more accurate. This includes things like coalescing adjacent chunks, merging chunks, and more. You will be informed if multiple chunks could fit inside of a single read.
Best Practices
In my experience, it's best to provide Cascade with more specific prompts rather than general, incomplete statements. You don't want to let Cascade wander into researching an area that isn't relevant to your work so you should be clear about what you're looking for. You can also prompt Cascade to look at specific websites or domains (ie. use the official NextJS docs).
You do not need to use @web and in some cases, I've found searching the web can sometimes be overkill. For example, if you're looking to generate a function and there's no real-time need, Cascade can likely do this entirely based on its training data. Forcing it to use the web can waste Flow Action credits and slow down the end to end experience.
One of the biggest challenges I had worked on was site compatibility. Websites are built very differently and it's difficult to build a web scraping system that works on every site. I considered outsourcing to a third party but that would both hinder our security posture as well as prevent you from reading documents within your network. I'm working on adding more site compatibility but if you find that the page read is not as useful as you'd expect (by clicking on the URL to view the markdown it read), consider prompting it to look at URLs that can be reliably scraped such as blog posts, document sites, StackOverflow, GitHub file links / issues, and more. Cases that are known to be problematic are things like paywalls, login pages, online editors (ie. CodeSandbox), and JS-heavy sites (ie. animated sites).
Conclusion
I hope this tutorial has been helpful in getting you started with Cascade web tools. If you have any feedback or questions, feel free to reach out at @kevinhou22!